 ElasticSearch杂记
ElasticSearch杂记
# 1 Elasticsearch常见基础问题
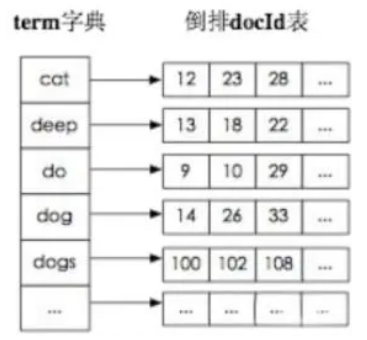
# 1.1 elasticsearch的倒排索引是什么?
例如:查询指定关键词的文章。
传统的检索是:遍历文章找到有对应的关键词。
倒排索引:通过分词策略,形成词和文章的映射关系表,这种词典+映射表即为倒排索引。
# 1.2 ES索引数据多了怎么办?
1.使用滚动索引。基于模板+时间+rollover api滚动创建索引。
2.只保留指定时间范围内数据。
3.动态增加节点。ES自身支持动态扩展。
# 1.3 生产ES的集群架构配置?
集群架构
ES的集群架构有23个节点,节点配置是16核64G的。
索引数据大小
该集群架构包括了订单服务和运单服务的索引,其中负责的运单服务包括寄件运单和派件运单索引。
索引根据录入时间每日递增(滚动索引)。当时每日新增数据两个索引大概四五千万,数据大小几十G。
分片数量
10个分片。5个主分片和5个副本分片。
# 2 文档映射
提示
ES中映射可以分为动态映射和静态映射
# 2.1 动态映射
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。
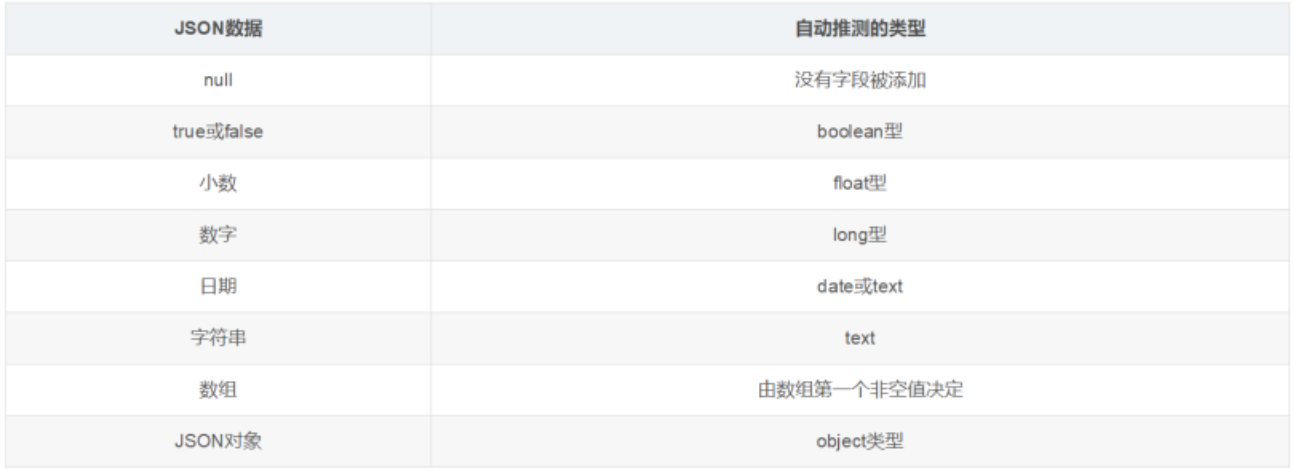
而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则
# 2.2 静态映射
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
例:
设置文档映射
PUT /es_db
{
"mappings":{
"properties":{
"name":{"type":"keyword","index":true,"store":true},
"sex":{"type":"integer","index":true,"store":true},
"age":{"type":"integer","index":true,"store":true},
"book":{"type":"text","index":true,"store":true},
"address":{"type":"text","index":true,"store":true}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
根据静态映射创建文档
PUT /es_db/_doc/1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "elasticSearch入门至精通",
"address": "广州车陂"
}
2
3
4
5
6
7
8
获取文档映射
GET /es_db/_mapping
# 3 ES乐观并发控制
实现_version乐观锁更新文档(旧版本)
POST /es_sc/_doc/1
{
"id": 1,
"name": "louis",
"desc": "louis blog",
"create_date": "2022-01-01"
}
POST /es_sc/_update/1
{
"doc": {
"name": "louis2"
}
}
PUT /es_sc/_doc/1?version=1
{
"name": "louis3"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
ES新版本7.x不使用version进行并发版本控制。if_seq_no=版本值&if_primary_term=文档位置。
_seq_no:文档版本号,作用同_version。_primary_term:文档所在位置。
PUT /es_sc/_doc/1?if_seq_no=1&if_primary_term=1
{
"name": "louis3"
}
PUT /es_sc/_doc/1?if_seq_no=2&if_primary_term=1
{
"name": "louis3"
}
2
3
4
5
6
7
8
9
if_seq_no 和 if_primary_term 是用来并发控制,他们和 version 不同。
seq_no:
version 属于单个文档,而 seq_no 属于整个 index 。
primary_term:
表示文档所在主分片的编号。
primary_term 和 seq_no 一样都是整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,primary_term 会递增1。
提示
primary_term 主要是用来恢复数据时处理当多个文档的 seq_no 一样时的冲突,比如当一个shard宕机了,raplica需要用到最新的数据,就会根据 primary_term 和 seq_no 这两个值来拿到最新的document
# 4 ES准实时索引实现
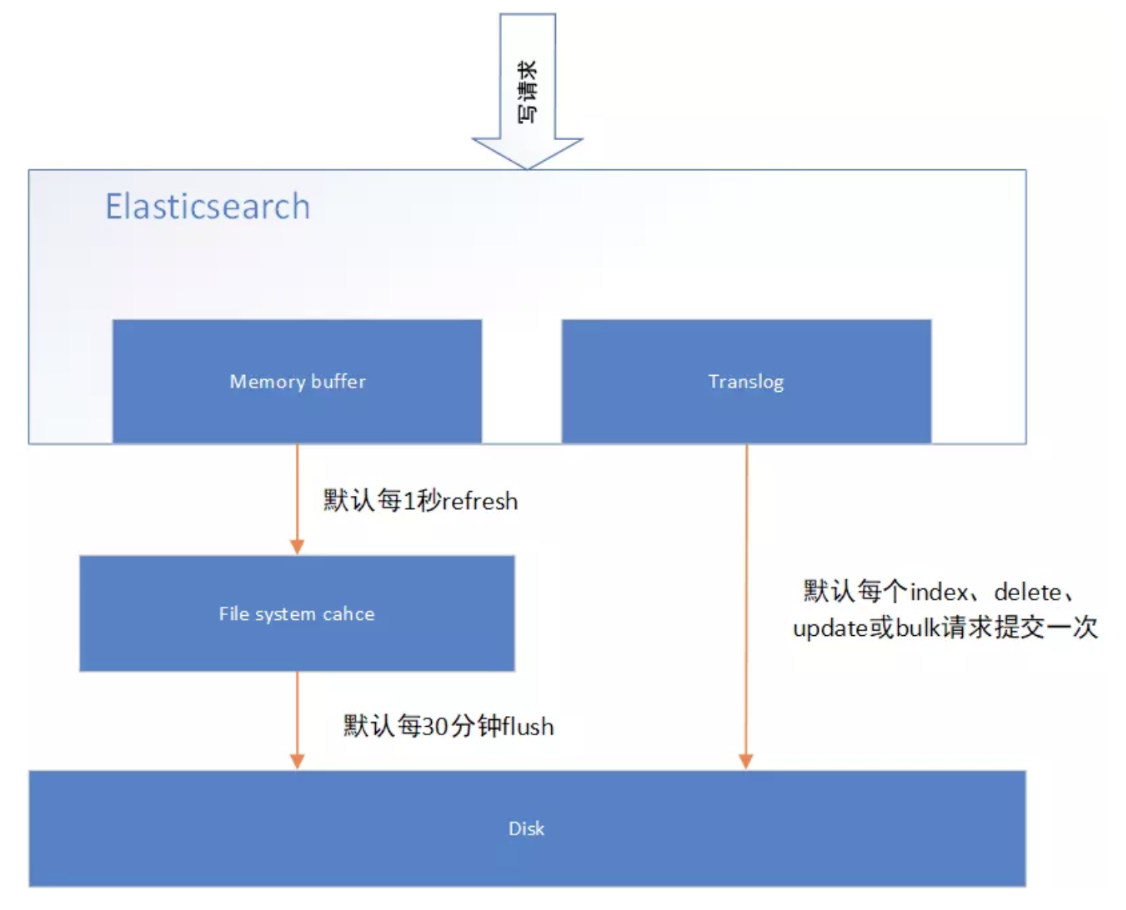
# 4.1 溢写到文件系统缓存
当数据写入到ES分片时,会首先写入到内存中,然后通过内存的buffer生成一个segment,并刷到文件系统缓存中,数据可以被检索(不是直接刷到磁盘)。
ES中默认1秒,refresh一次。
缓冲文件系统
缓冲文件系统的特点是:在内存开辟一个 缓冲区 ,为程序中的每一个文件使用,当执行读文件的操作时,从磁盘文件将数据先读入内存 缓冲区 ,装满后再从内存 缓冲区 依次读入接收的变量。
执行写文件的操作时,先将数据写入内存 缓冲区 ,待内存 缓冲区 装满后再写入文件。
由此可以看出,内存 缓冲区 的大小,影响着实际操作外存的次数,内存 缓冲区 越大,则操作外存的次数就少,执行速度就快、效率高。一般来说,文件 缓冲区 的大小随机器而定。
# 4.2 写translog保障容错
在写入到内存中的同时,也会记录 translog 日志,在 refresh 期间出现异常,会根据translog来进行数据恢复。
等到文件系统缓存中的 segment 数据都刷到磁盘中,清空 translog 文件。
# 4.3 flush到磁盘
ES默认每隔30分钟会将文件系统缓存的数据刷入到磁盘。
# 4.4 segment合并
Segment太多时,ES定期会将多个segment合并成为大的segment,减少索引查询时IO开销,此阶段ES会真正的物理删除(之前执行过的delete的数据)。
# 5 ES集群脑裂问题
集群脑裂是什么?
同一个集群中的不同节点,对于集群的状态有了不一样的理解,比如集群中存在两个master。
master是集群中非常重要的一个角色,主宰了集群状态的维护,以及shard的分配,因此如果有两个master,可能会导致数据异常。
解决方案 选举master节点时,需要超过半数的候选节点才可以选举,否则不允许选举master。
这个选举算法就是:
master候选节点数量 / 2 + 1 。
假如有10个候选节点,那么需要10/2 + 1 = 6,即至少需要有6个节点才能开始选举。
假如只有2个候选节点,那么2/2 + 1 = 2。这样如果一个节点挂掉了,剩下一个节点没有满足超过半数,也就无法选举出新的master。
综上所述ES集群中节点的数量至少3台,3个节点通过在elasticsearch.yml中配置discovery.zen.minimum_master_node:2,就可以避免脑裂问题的产生。
# 6 scroll分页查询
# 6.1 使用from和size
在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页。
POST /es_db/_doc/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"address": "深圳南山"
}
}
}
2
3
4
5
6
7
8
9
10
# 6.2 使用scroll方式分页
前面使用from和size方式,查询在1W条数据以内都是OK的,但如果数据比较多的时候,会出现性能问题。
Elasticsearch做了一个限制,不允许查询的是10000条以后的数据。如果要查询10000条以后的数据,需要使用Elasticsearch中提供的scroll游标来查询。
提示
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。
使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。
使用scroll查询后,排序后的数据会保持一定的时间,后续的分页查询都从该快照取数据即可。
第一次使用scroll分页查询
此处,我们让排序的数据保持1分钟,所以设置scroll为1m
GET /es_db/_search?scroll=1m
{
"query": {
"multi_match": {
"query": "广州长沙张三",
"fields": [
"address",
"name"
]
}
},
"size": 100
}
2
3
4
5
6
7
8
9
10
11
12
13
执行后,结果返回以下信息:
"_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAZEWY2VQZXBia1JTVkdhTWkwSl9GaUYtQQ=="
第二次直接使用scroll id进行查询
GET _search/scroll?scroll=1m
{
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAZoWY2VQZXBia1JTVkdhTWkwSl9GaUYtQQ=="
}
2
3
4
# 7 RestHighLevelClient的使用
提示
ES官网推荐的ES客户端组件RestHighLevelClient, 其封装了操作ES的CRUD方法,底层原理就是模拟各种ES需要的请求,如PUT,POST,DELETE,GET等方式
# 7.1 依赖包引入
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.8.1</version>
</dependency>
2
3
4
5
# 7.2 查询
public class Test {
public void search() {
// 构建查询参数
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 指定返回字段
String[] includes = new String[]{"name", "age"};
String[] excludes = new String[]{"sex"};
searchSourceBuilder.fetchSource(includes, excludes);
// 构建条件查询
// and = filter/must; or = should
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
searchSourceBuilder.query(boolQueryBuilder.filter(QueryBuilders.termsQuery("id", ids)));
// 时间范围查询
searchSourceBuilder.query(boolQueryBuilder.filter(QueryBuilders.rangeQuery("created_time").from(queryVO.getCreatedTime())));
searchSourceBuilder.query(boolQueryBuilder.filter(QueryBuilders.rangeQuery("created_time").to(queryVO.getEndTime())));
// 分页
Integer size = queryVO.getSize();
Integer from = (queryVO.getPage() - 1) * queryVO.getSize();
if (size + from > 10000) {
throw new RRException("分页参数不合理,暂不处理");
}
searchSourceBuilder.size(size);
searchSourceBuilder.from(from);
searchSourceBuilder.query(boolQueryBuilder);
// 构建请求
SearchRequest searchRequest = new SearchRequest(EsOperateTables.EXCEPTION_HANDLE.getAlias());// ES索引别名
searchRequest.source(searchSourceBuilder);
// 发起请求
SearchResponse searchResponse = new SearchResponse();
try {
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error(ErrorMsgConstant.ES_QUERY_ERROR, e);
throw new RRException(ErrorMsgConstant.ES_QUERY_ERROR);
}
// 解析SearchResponse
long totalHits = searchResponse.getHits().getTotalHits();
List<Map<String, Object>> mapList = Lists.newArrayListWithCapacity(searchResponse.getHits().getHits().length);
Arrays.stream(searchResponse.getHits().getHits()).forEach(hit -> mapList.add(hit.getSourceAsMap()));
List<ResInfo> resInfos = new ArrayList<>();
if (CollectionUtils.isNotEmpty(mapList)) {
resInfos = JSON.parseArray(JSON.toJSONString(mapList), ResInfo.class);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45