索引
索引
# 1 使用索引注意事项
1.在经常需要搜索的列上创建索引,加快搜索速度。
2.在where子句中的列上面创建索引,加快条件判断速度。
3.在经常需要排序的列上创建索引,加快排序查询时间。
4.在经常用在连接的列上(主要是一些外键)创建索引,加快连接速度。
5.中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引。
6.避免where子句中对字段施加函数,这会造成无法命中索引。
7.使用innoDB时用与业务无关的自增主键,即使用逻辑主键而不要用业务主键。
8.打算加索引的列设置为not null,否则将导致引擎放弃使用索引而进行全表扫描。
9.删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗。
# 2 调优
1.分库分表,读写分离
2.拆sql
3.建索引
4.sql优化
- like,尽量不在关键词前加%
- 尽量多表连接查询,避免子查询
- 合理的增加冗余的字段
- 减少使用IN或者NOT IN ,使用exists,not exists或者关联查询语句替代
提示
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的:
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
- or 的查询尽量用 union或者union all 代替。
虽然这两个方式都用到了索引,但 UNION 是用一个明确的值到索引中查找,目标非常明确,OR 需要对比两个值,目标相对要模糊一些,所以 OR 在恍惚中落后了
当MySQL单表记录数过大时,数据库的CRUD性能会明显下 降,一些常见的优化措施如下:
1. 限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时 候,我们可以控制在一个月的范围内。;
2. 读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
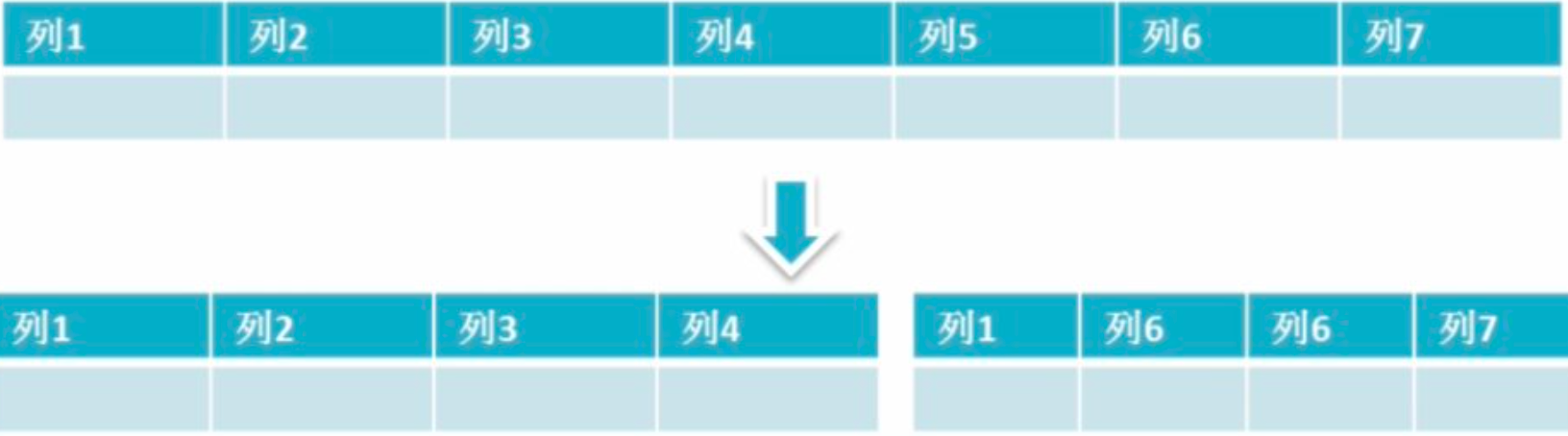
3. 垂直分区: 根据数据库里面数据表的相关性进行拆分。 把一张列比较多的表拆分为多张表。 如下图所示,这样来说大家应该就更容易理解了。
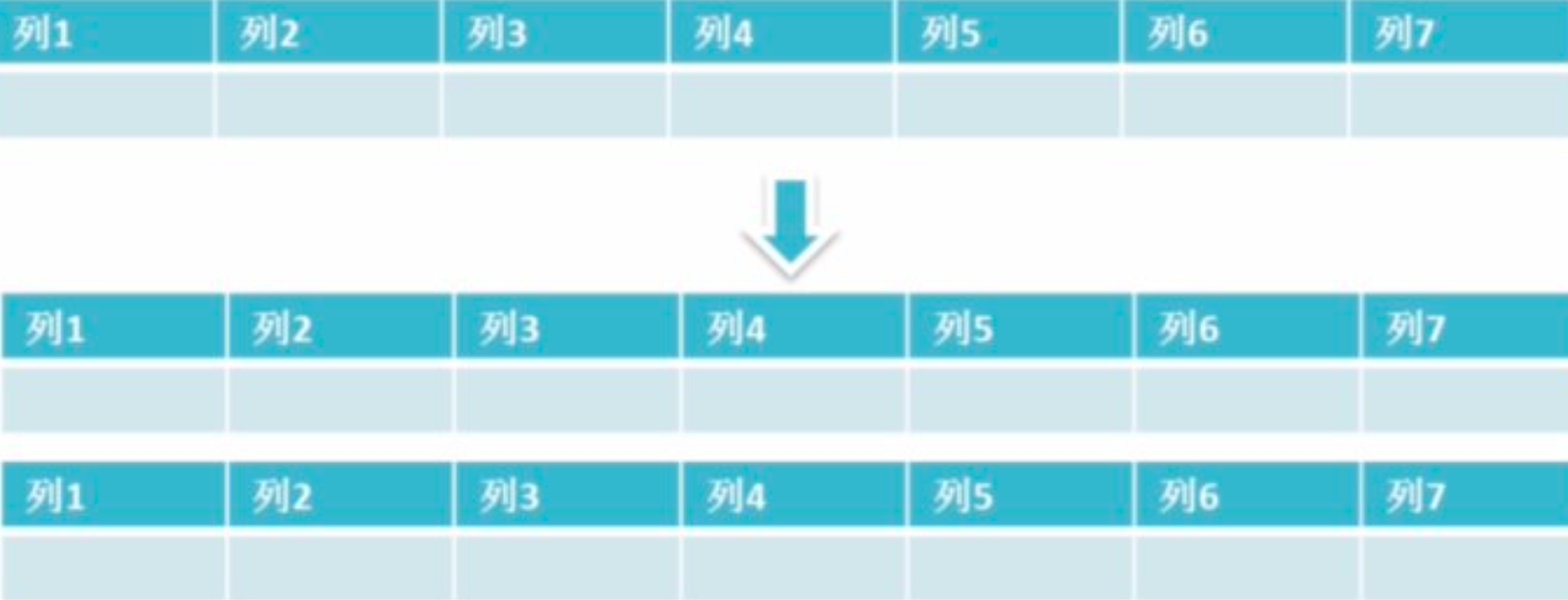
4. 水平分区: 水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。
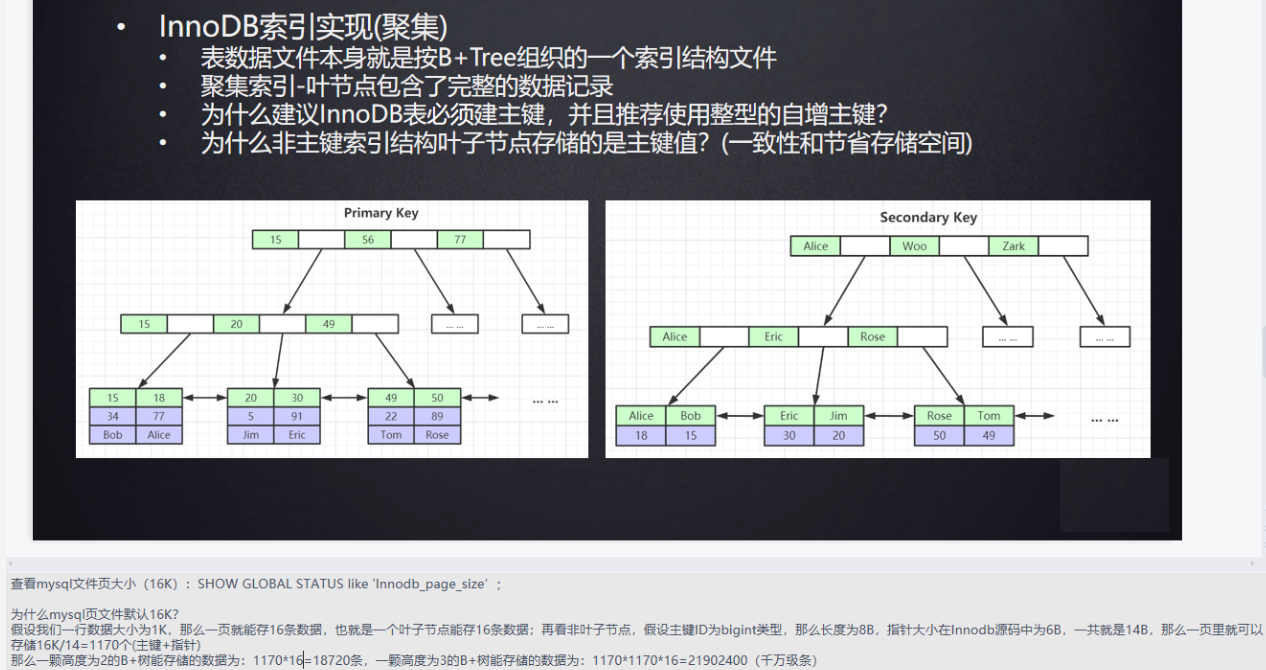
# 3 InnoDB和MyISam
# 3.1 InnoDB和MyISam的数据结构?
InnoDB和MyIsam是B+树索引
要加快索引 的查找速度则需要降低树的高度,要降低树的高度可通过增加树节点中数据的个数(度)实现。因为节点的数据是从磁盘加载的,磁盘加载数据的速度相对内存来说是很慢的,所以节点中数据不是越多越好,因为太多的话可能要多次 IO才能加载完,这样效率就会变低,所以B+树节点存储的数据大小尽量保证与一次IO读取数据大小一致,由于一次IO读取的数据较大(16K?),所以树的高度不高,即查找的次数很少就能找到目标数据。
1)MyISam非聚集索引 B+树结构 数据与索引分开存储,指向数据的地址存储在节点中
2)InnoDB聚集索引 B+树结构 数据与索引存储在一起,数据存储在叶子节点
# 3.2 mysql推荐用自增主键原因?
1)占用空间小,一次IO加载的数据多。
2)数字比较比字符串比较消耗小。
3)新增数据时自增主键都是顺序插入到B+树结构,而uuid之类的字符串主键计算后可能是插入到B+树中间的节点,这样会导致更多的计算消耗。
# 3.3 什么是覆盖索引?
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。InnoDB引擎中,如果不是主键索引,叶子节点存储的是主键+列值,最终还是要“回表”,也就是通过主键再查找一次。这样比较慢。覆盖索引就是要查询出的列和索引是对应的,不做回表操作。
例子:
ALTER TABLE `test_table` ADD INDEX `idx_col1_col2_col3`(`col1`,`col2`,`col3`);
分析查询:
EXPLAIN
SELECT SQL_NO_CACHE col2, col3 FROM test_table WHERE col1 = xxx ORDER BY col2;
2
结果:建立联合索引后,type 为 ref,使用了 idx_col1_col2_col3 索引,Extra 为 Using index,说明使用了覆盖索引。
# 3.4 怎么添加索引?
1.添加PRIMARY KEY(主键索引)
ALTER TABLE `table_name` ADD PRIMARY KEY (`column`);
2.添加UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE (`column`);
3.添加INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name (`column`);
4.添加多列索引
ALTER TABLE `table_name` ADD INDEX index_name (`column1`, `column2`, `column3`);
# 3.5 MYSQL数据量估算