 表格存储
表格存储
本篇内容来源于阿里云-表格存储官网:https://help.aliyun.com/product/27278.html (opens new window)
# 1.1 什么是表格存储?
表格存储(Tablestore)面向海量结构化数据提供Serverless表存储服务,同时针对物联网场景深度优化提供一站式的IoTstore解决方案。适用于海量账单、IM消息、物联网、车联网、风控、推荐等场景中的结构化数据存储,提供海量数据低成本存储、毫秒级的在线数据查询和检索以及灵活的数据分析能力。
# 1.2 功能特性
# 多模型数据存储
表格存储(Tablestore)提供了宽表(WideColumn)模型、时序(TimeSeries)模型和消息(Timeline)模型三种数据存储模型。
宽表模型 (opens new window):类Bigtable/HBase模型,可应用于元数据、大数据等多种场景,支持数据版本、生命周期、主键列自增、条件更新、局部事务、原子计数器、过滤器等功能。
时序模型 (opens new window):针对时间序列数据的特点进行设计的模型,可应用于物联网设备监控、设备采集数据、机器监控数据等场景,支持自动构建时序元数据索引、丰富的时序查询能力等功能。
消息模型 (opens new window):针对消息数据场景设计的模型,可应用于IM、Feed流等消息场景。能满足消息场景对消息保序、海量消息存储、实时同步的需求,同时支持全文检索与多维度组合查询。
网格模型 (opens new window):Grid模型(网格模型)是表格存储针对多维网格数据(科学大数据)设计的模型。
# 多元化数据索引
除了支持主键查询,表格存储还支持二级索引和多元索引的索引方式,提供强大的数据查询能力。
- 数据表主键:数据表类似于一个巨大的Map,它的查询能力也就类似于Map,只能通过主键查询。
- 二级索引:通过创建一张或多张索引表,使用索引表的主键列查询,相当于把数据表的主键查询能力扩展到了不同的列。
- 多元索引:使用了倒排索引、BKD树、列存等结构,具备丰富的查询能力,例如非主键列的条件查询、多条件组合查询、地理位置查询、全文检索、模糊查询、嵌套结构查询、统计聚合等。
# 冷热分层存储
数据存储支持自动冷热分层,同时表格存储支持高性能实例和容量型实例两种实例规格来满足不同业务的数据存储需求。
- 高性能实例:适用于对读写性能和并发都要求非常高的场景,例如游戏、金融风控、社交应用、推荐系统等。
- 容量型实例:适用于对读性能不敏感,但对成本较为敏感的业务,例如日志监控数据、车联网数据、设备数据、时序数据、物流数据、舆情监控等。
# 数据湖投递
将表数据全量备份或实时投递数据到数据湖OSS中存储。投递的数据兼容开源生态标准,按照Parquet列存格式存储,兼容Hive命名规范。您可以使用数据湖分析DLA和E-MapReduce直接对投递到OSS的数据进行外表分析。
提示
有关Tablestore的功能特性详细介绍,可点击此链接获取 功能特性 (opens new window)
# 1.3 产品架构
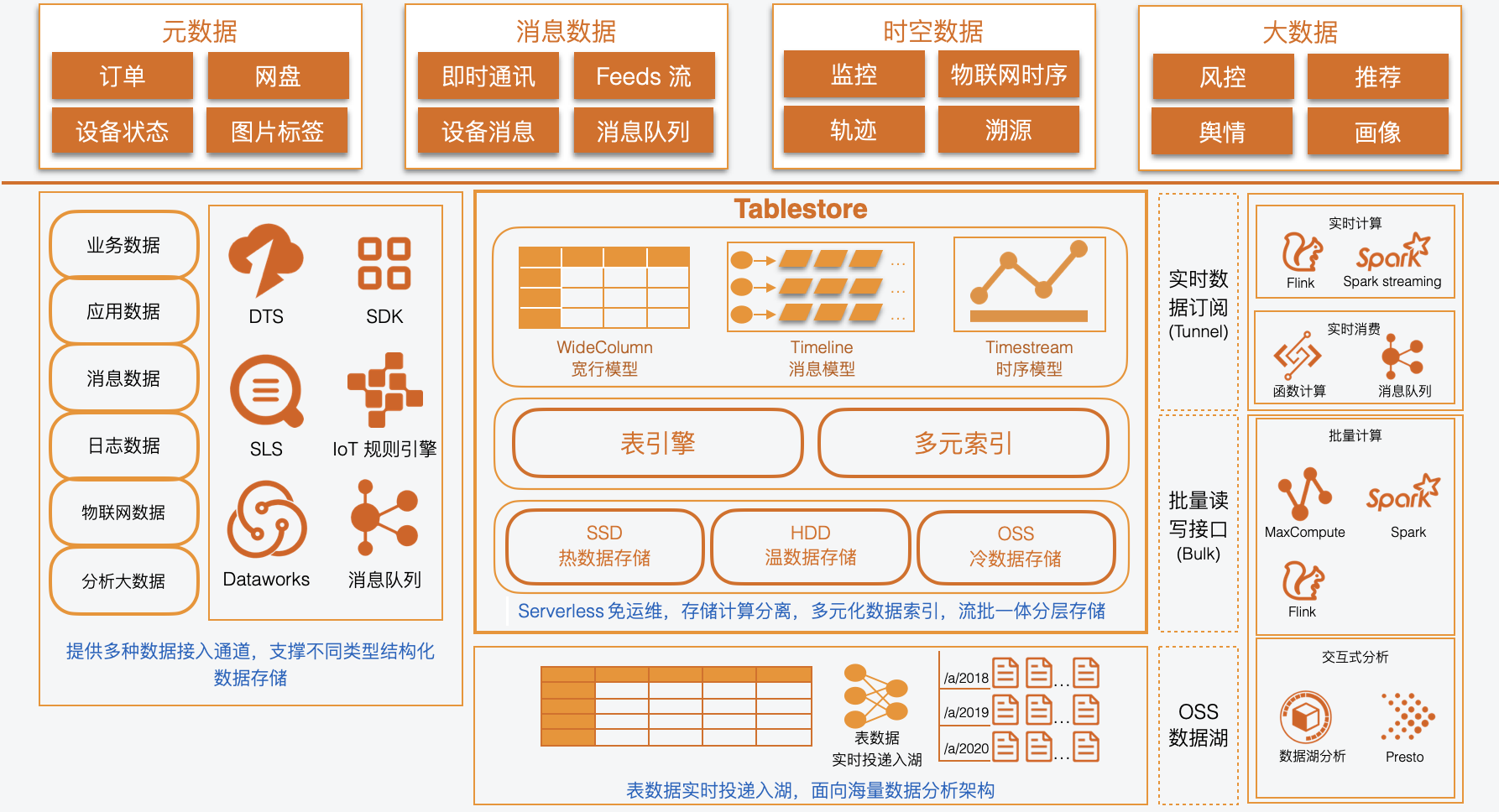
业务场景
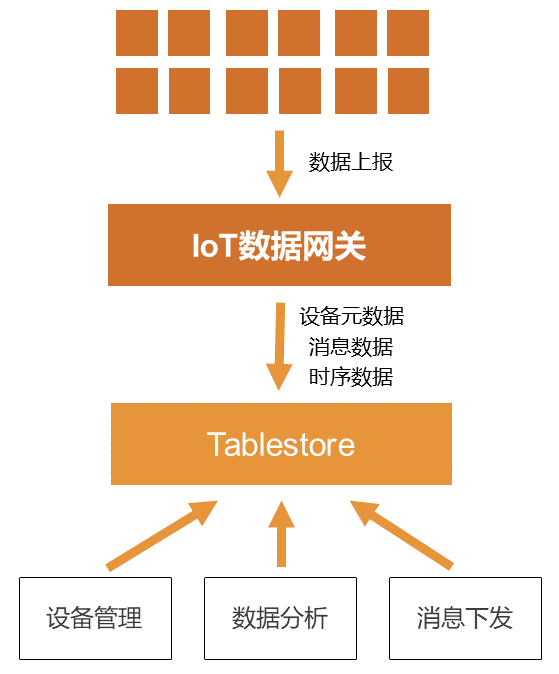
表格存储适用于元数据、消息数据、时空数据、大数据等场景下的系统搭建。
数据接入
表格存储提供SDK、DataWorks、IoT规则引擎等多种数据接入方式,支撑应用数据、消息数据、物联网数据等不同类型结构化数据的存储。
计算生态对接
- 表格存储提供SDK、DataWorks、IoT规则引擎等多种数据接入方式,支撑
- 应用数据、消息数据、物联网数据等不同类型结构化数据的存储。
典型应用架构
根据使用场景不同,表格存储有互联网应用架构、数据湖架构和物联网架构三种典型应用架构。
1、互联网应用架构
互联网应用架构包括数据库分层架构和分布式结构化数据存储架构,主要用于电商订单、直播弹幕、网盘中文件元数据、社交网络中即时通讯等场景。
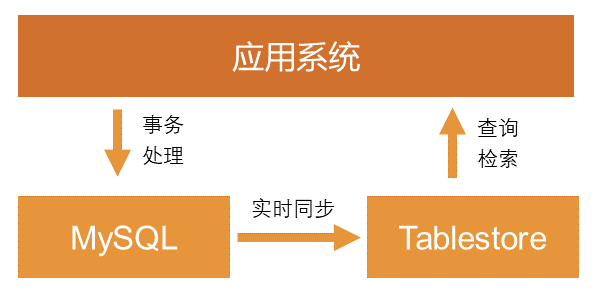
(1)数据库分层架构
在数据库分层架构中,使用Tablestore配合MySQL来完成应用系统的业务需求,利用MySQL的事务能力来处理对事务强需求的写操作与部分读操作,利用Tablestore的数据检索能力和大数据存储来实现数据存储、查询与分析。
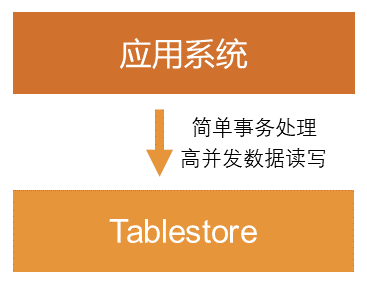
(2)分布式结构化数据存储架构
在分布式结构化数据存储架构中,Tablestore直连应用系统实现简单的事务处理和高并发数据读写。
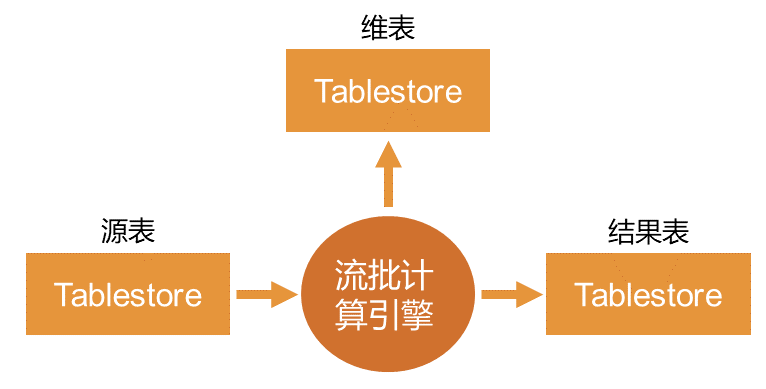
2、数据湖架构
数据湖架构主要用于数据中台、推荐系统、风控系统等场景。 在数据湖架构中,表格存储作为源表、结果表或者维表对接流批计算引擎实现大数据计算与分析。
3、物联网架构
物联网架构主要用于车联网、智能家电、工业物联网、物流等场景。 在物联网架构中,表格存储作为IoT基础设施中的统一数据存储平台来存储物联网平台相关的时序数据、元数据、消息数据等,并提供丰富的数据分析处理能力。
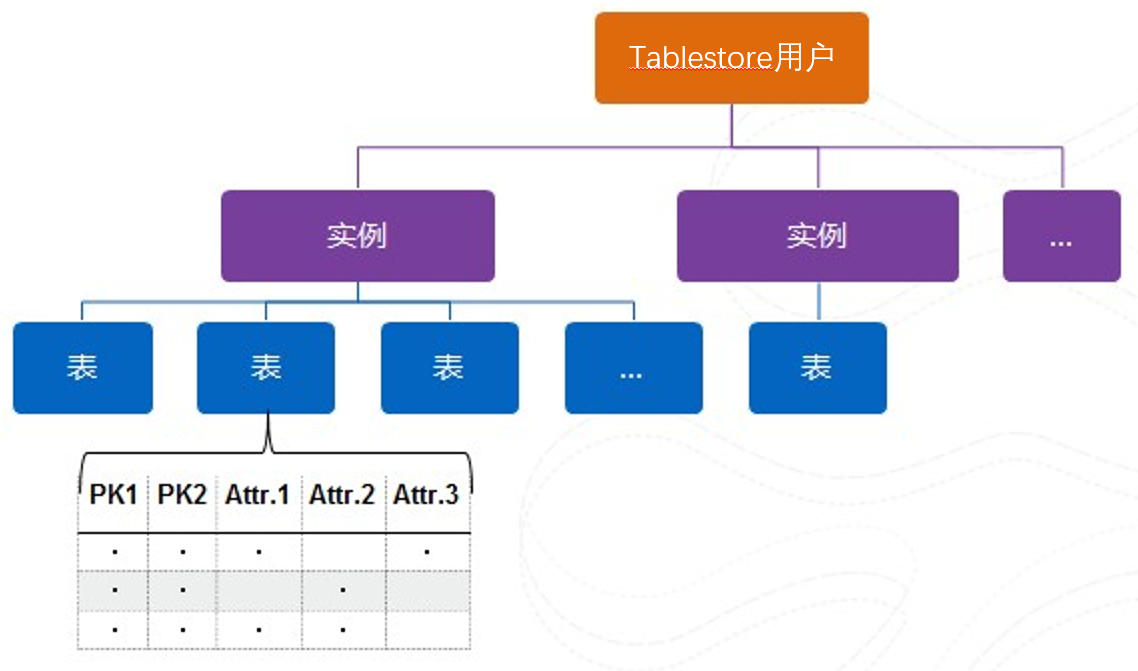
# 1.4 基础概念
- 实例(Instance)
使用和管理表格存储服务的实体,每个实例相当于一个数据库。
高性能实例
(1)适用场景:适用于对读写性能和并发都要求非常高的场景,例如游戏、金融风控、社交应用、推荐系统等。
(2)计费类型:预留读吞吐量或写吞吐量、按量读吞吐量或按量写吞吐量
容量型实例:
(1)适用场景:适用于对读写性能和并发都要求非常高的场景,例如游戏、金融风控、社交应用、推荐系统等。
(2)计费类型:按量读吞吐量或按量写吞吐量
服务地址( Endpoint)
每个表格存储实例对应一个服务地址,应用程序进行表和数据操作时需要指定服务地址。不同访问场景下需使用相应的服务地址格式。
- 读写吞吐量
读/写吞吐量的单位为读服务能力单元和写服务能力单元,简称<mark>CU</mark>(Capacity Unit),是数据读写操作的最小计费单位。当通过表格存储的API对数据表进行读写操作时,会消耗对应的写服务能力单元和读服务能力单元。
(1)1单位读服务能力单元表示从数据表中读一条4 KB数据。 (2)1单位写服务能力单元表示向数据表写一条4 KB数据。 (3)操作数据大小不足4 KB的部分向上取整,例如写入7.6 KB数据消耗2单位写服务能力单元,读出0.1 KB数据消耗1单位读服务能力单元。
预留读/写吞吐量
预留读/写吞吐量是高性能实例中数据表的一个属性。在创建数据表时,可以为数据表指定预留读/写吞吐量。
当设置的预留读/写吞吐量大于0时,表格存储会为数据表分配和预留相应的资源,每秒对数据表的访问不超过预留读/写吞吐量时将按照预留读/写吞吐量的单价计费。
当设置的预留读/写吞吐量等于0时,表格存储不会为数据表分配和预留相应的资源。
由于预留读/写吞吐量在单价上低于按量读/写吞吐量,配置合适的预留读/写吞吐量可以进一步降低成本。
<mark>注意:容量型实例下的数据表不支持预留读/写吞吐量。</mark>
按量读/写吞吐量
按量读/写吞吐量是数据表在每秒实际消耗的读/写吞吐量中超出预留读/写吞吐量的部分,统计周期为1秒。每个小时内,表格存储对预留读/写吞吐量取平均值,对按量读/写吞吐量取累加值来作为用户实际消耗的吞吐量。
由于按量读/写吞吐量的模式无法预估需要为数据表预留的计算资源,表格存储需要提供足够的服务能力以应对突发的访问高峰,所以按量读/写吞吐量的单价高于预留读/写吞吐量的单价。
- 地域
地域(Region)是指阿里云物理数据中心所在的位置。表格存储部署在多个地域中。
- 数据生命周期
数据生命周期(Time To Live,简称TTL)是数据表的一个属性,即数据的存活时间,单位为秒。表格存储会在后台对超过存活时间的数据进行清理,以减少您的数据存储空间,降低存储成本。